
Health Assessment and Performance Monitoring of Large Machine Diagnostics
Project # 23-003 | Year 2 of 2
Jesse Adamsa, Nick Eisenberga, Ethan Chessonb, Arnulfo Gonzaleza, Marylesa Howarda, Margaret Lundc
aNevada National Security Sites (NNSS), bNorth Carolina A&T State University, cNational Lab: PNNL
This work was done by Mission Support and Test Services, LLC, under Contract No. DE-NA0003624 with the U.S. Department of Energy, the NNSA Office of Defense Programs, and supported by the Site-Directed Research and Development Program. DOE/NV/03624–1920.
Abstract
Regularly maintained and operated diagnostic machines are a backbone of data collection for the Stockpile Stewardship Program. Component failures can result in catastrophic downtime for the diagnostic, affecting schedules, cost, and performance. For example, the age of the Cygnus x‐ray machine at U1a requires additional upkeep and maintenance, and the change in behavior (e.g., arcing in the water line) or failure of components (e.g., capacitors) can result in days of lost data collection due to troubleshooting and repairs. In this project, we will build models to monitor performance of Cygnus. By monitoring performance of the machine using various measurements, like electrical current and voltage at multiple points on the path of the machine, we expect to be able to assess health, observe declining performance, and predict failures.
Background
Cygnus has lasted well beyond its originally intended lifespan, and thus some parts have more wear than ever intended. Faults in these parts have caused delays in experiments, and the ability to foresee and/or diagnose such failures can help ensure experiments are timely and successful.
Technical Approach
Cygnus has a long and fruitful history of supporting subcritical experiments by providing x‐rays for radiographic images. Quantifying its health and future behavior may reduce maintenance costs, decrease frequency and duration of downtime to troubleshoot issues, and eliminate would‐be failed shots. One issue over recent years has been capacitor failure. Pulsed‐power subject matter expert, John Smith, believes that a capacitor in pre‐failure status may provide clues in its electrical signals. If this is true and quantifiable, then decline of a capacitor should be observable with the right diagnostics, and predictable by the right mathematical model.
Machine learning (ML) is a broad term used to describe mathematical models in which a computer identifies or “learns” patterns in a dataset and can then make predictions based on those patterns. Supervised ML exploits patterns in training data (data with a known true/desired output prediction) to learn relationships between inputs and outputs and make predictions based on those relationships. There are many years’ worth of diagnostic data on Cygnus, with the number of individual diagnostics numbering anywhere from 20-30 on each axis at any given time. This library, along with the catalogue of shot logs describing Cygnus’ performance in dose (rads), provides a perfect dataset of inputs/outputs for harnessing the power of machine learning for Cygnus modeling purposes.
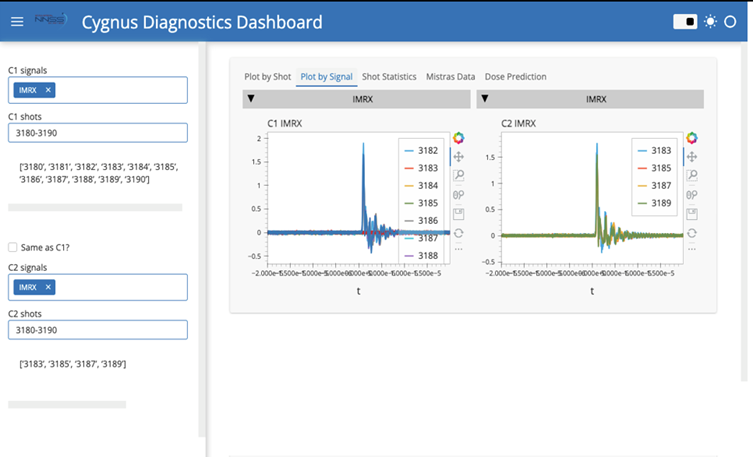
In the first year of the project, we focused on establishing a knowledgebase of Cygnus, and collecting and organizing the data consisting of 100 GB of past experiment results in binary data formats. We wrote Python scripts to translate these binary files into a useable file format, with one CSV file for each shot. Concurrently, we combined records of each shot into a single master shot log. This included recorded data from the Cygnus team, the radiography analysts, Nichelle Prock, and the lithium fluoride thermal luminescent dosimeter spreadsheets. Once the dataset was properly labeled and organized, we started the analysis. Using 20‐30 signals for thousands of shots is too computationally expensive for a standard computer, so we reduced our dataset to a few figures of merit (FOMs). Using these FOMs, we successfully trained models to predict shot dose. In the second year, we worked with the Cygnus team to add an additional set of sensors to the Cygnus Marx Banks. These sensors from Mistras will help identify capacitor failures in the future, helping to save time in locating problematic capacitors, as well as potentially providing an indication of an impending failure. Concurrently, we built a dashboard for the Cygnus team that allows an analyst to view the raw data, compare signals between shots, and see statistics and predictions using our ML models.
Results and Technical Accomplishments
We developed and trained Neural Networks capable of predicting next shot dose with some reasonable accuracy. We produced a Cygnus Dashboard for analysts to easily see and compare data. We were able to install a new set of Mistras sensors on Cygnus to help diagnose future capacitor issues.
Conclusions and Path Forward
This was the final year of the project. We will continue to support the Cygnus team where possible with the Mistras sensors and the dashboard.
Back to Accelerator Beam Science and Target Interactions Index