
Utilizing Machine Learning to Automate Linear Induction Accelerator Beam Tuning
Project #: 22-068 | Year 1 of 2
Daniel Clayton,a Rachel Gilyard,a Jesse Adams,a Sean Breckling,a Jeremy Fait,a Jason Koglinb
aNevada National Security Site; bLos Alamos National Laboratory
Executive Summary
Sorting algorithms are being applied to historical Dual-Axis Radiographic Hydrodynamic Test (DARHT) Axis 2 accelerator data to search for abnormal conditions within the large dataset. These algorithms will then be applied to accelerator data in real time to predict machine component failure.
Description
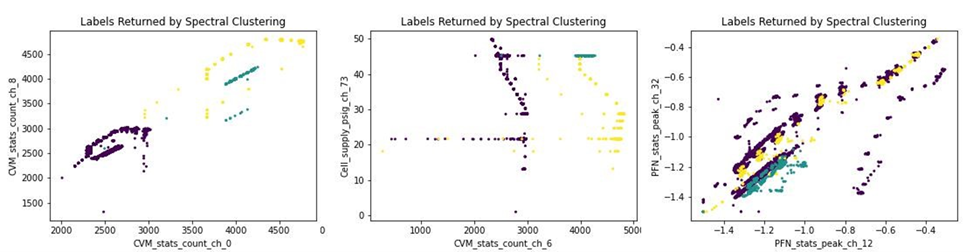
Historical pulsed power data from Axis 2 of the DARHT Facility were compiled, and a shared, secure computational workspace was created on the DARHT computer network to access this data and to write analysis code in a collaborative, version-controlled environment. This dataset is comprised of 6,216 variables from each Axis 2 pulse over the years, both with and without beam present. Code was written to access this data and apply different clustering algorithms with a GUI interface. First, the dataset was reduced to include only variables that had values for each pulse within the set, then clustering algorithms were applied. One particular clustering algorithm, spectral clustering, has proven the most robust for this analysis. The next step will be to optimize the clustering parameters to group the data into meaningful operational conditions, then to look for outlying shots. The figure below shows an initial application of spectral clustering to the data using three clusters. Each plot highlights two of the thousands of variables the algorithm is applied to; further development is needed to improve visualization of this large dataset. Note that the DARHT team has not provided context to the physical meaning of these variables so as to not bias the initial analysis. Once the algorithm is optimized, the project team will present results to the DARHT team to learn about the operating conditions of the outlying datapoints and to verify the success of the algorithm.
Conclusion
Initial results are promising, but much work remains. The spectral clustering parameters must be optimized and abnormal accelerator conditions identified, then the algorithm needs to be applied to new data. Additionally, algorithms will be developed to include beam monitor data to cluster beam tune parameters, to be used for automated beam tuning routines.
Mission Benefit
Component failures do happen from time to time during routine operation of linear induction accelerators (LIAs) used for radiography. An unexpected failure occurring during a hydrodynamic or subcritical experiment would be catastrophic, causing a loss of data on a very valuable experiment. The pulsed power datasets collected from LIA operations are vast, and small abnormalities typically go unnoticed by human eyes. Using clustering algorithms to predict machine failure and to identify the failing component before it happens, operators could replace parts before a catastrophic failure leads to loss of data.
This work was done by Mission Support and Test Services, LLC, under Contract No. DE-NA0003624 with the U.S. Department of Energy. DOE/NV/03624–1634.
Return to Accelerator Beam Science and Target Interactions
Go to SDRD Annual Report Index
Return to SDRD Homepage